

- 论文标题:Mean Flows for One-step Generative Modeling
- 论文地址:https://arxiv.org/pdf/2505.13447v1
文章提出了一种名为MeanFlow的单步生成建模框架。在科研的道路上,我们常常会遇到各种挑战和难题,就像在黑暗中摸索前行。而生成模型就像是一盏明灯,它旨在将先验分布转换为数据分布。流匹配提供了一个直观且概念简单的框架,用于构建将一个分布传输到另一个分布的流路径。它与扩散模型密切相关,但关注的是引导模型训练的速度场。自引入以来,流匹配已在现代生成模型中得到广泛应用,成为了科研领域的一颗璀璨明星。而MeanFlow的出现,就像是在这颗明星的基础上,又增添了一抹绚丽的色彩。它通过引入平均速度(average velocity)的概念来改进现有的流匹配方法。这就好比在一条原本已经畅通的道路上,找到了一条更加便捷、高效的捷径。在ImageNet 256×256数据集上,MeanFlow取得了显著优于以往单步扩散 / 流模型的结果,FID分数达到3.43,且无需预训练、蒸馏或课程学习。这一成果,无疑是科研道路上的一次重大突破,让我们看到了未来的无限可能。
MeanFlow就像是一个充满智慧的探险家,它的核心思想是引入一个新的ground - truth场来表示平均速度,而不是流匹配中常用的瞬时速度。这就像是在观察一个物体的运动时,我们不再仅仅关注它某一时刻的速度,而是更全面地考虑它在一段时间内的平均速度。文章提出使用平均速度(在时间间隔内的位移与时间的比值)来代替流匹配中通常建模的瞬时速度。然后推导出平均速度与瞬时速度之间存在一个内在的关系,从而作为指导网络训练的原则性基础。基于这一基本概念,训练了一个神经网络来直接建模平均速度场,并引入损失函数来奖励网络满足平均速度和瞬时速度之间的内在关系。进一步证明,该框架可以自然地整合无分类器引导(CFG),并且在采样时无需额外成本。
MeanFlow在单步生成建模中表现出了强大的性能。在ImageNet 256×256数据集上,仅使用1 - NFE(Number of Function Evaluations)就达到了3.43的FID分数。这一结果显著优于之前同类方法的最佳水平,相对性能提升达到50%到70%(见图1)。就像一场激烈的比赛,MeanFlow以绝对的优势脱颖而出,让我们感受到了科技的魅力和力量。
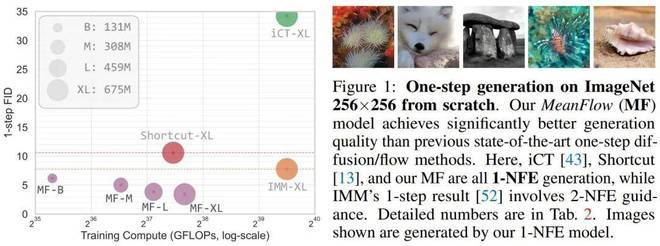
此外,MeanFlow是一个自成一体的生成模型:它完全从头开始训练,没有任何预训练、知识蒸馏或课程学习。这就像是一个白手起家的创业者,凭借着自己的努力和智慧,创造出了属于自己的辉煌。该研究大幅缩小了单步扩散 / 流模型与多步研究之间的差距,让我们看到了科技进步的巨大潜力。
方法介绍
MeanFlow核心思想是引入一个代表平均速度的新场。平均速度u可表示为:

其中,u表示平均速度,v表示瞬时速度。u (z_t,r,t)是一个同时依赖于(r, t)的场。u的场如图3所示:

平均速度u是瞬时速度v的函数,即,它是由v诱导的场,不依赖于任何神经网络。

进一步的,为了得到适合训练的公式,本文将Eq.(3)改写为:

然后两边对t求导,把r看作与t无关的变量,得到:

其中左侧的运算采用乘积法则,右侧的运算采用微积分。重新排列项,得到恒等式:
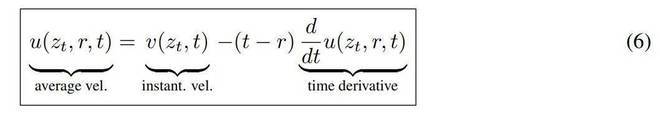
这个方程称为MeanFlow恒等式,它描述了v和u之间的关系。图1给出了最小化损失函数的伪代码。

单步采样

实验效果如何?
实验是在256×256 ImageNet数据集上进行的。图1中,本文将MeanFlow与之前的单步扩散 / 流模型进行了比较,如表2(左)所示。总体而言,MeanFlow的表现远超同类:它实现了3.43的FID,与IMM的单步结果7.77相比,相对提升了50%以上。如果仅比较1 - NFE(而不仅仅是单步)生成,MeanFlow与之前的最佳方法(10.60)相比,相对提升了近70%。不难看出,本文方法在很大程度上缩小了单步和多步扩散 / 流模型之间的差距。就像在一场长跑比赛中,原本差距较大的选手,通过不断努力和创新,逐渐缩小了与领先者的距离。
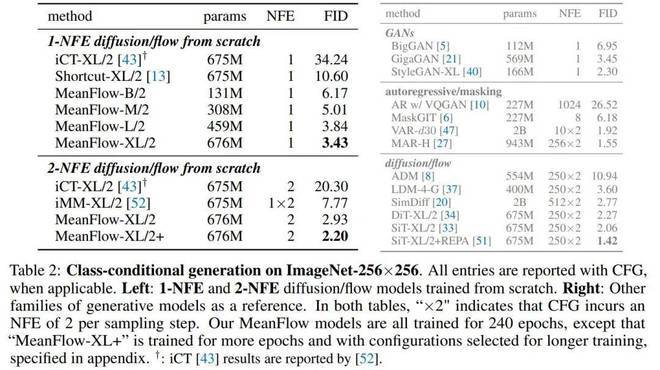
在2 - NFE生成中,MeanFlow实现了2.20的FID(表2左下)。这一结果与多步扩散 / 流模型的领先基线模型相当,即DiT (FID 2.27)和SiT (FID 2.15),两者的NFE均为250×2(表2右)。这一结果表明,few - step扩散 / 流模型可以媲美其多步模型。值得注意的是,本文方法是独立的,完全从头开始训练。它无需使用任何预训练、蒸馏或课程学习,就取得了出色的结果。这让我们不禁感叹,科研的道路上,只要有创新和坚持,就有可能创造出奇迹。
表3报告了在CIFAR - 10(32×32)上的无条件生成结果,本文方法与先前的方法相比具有竞争力。
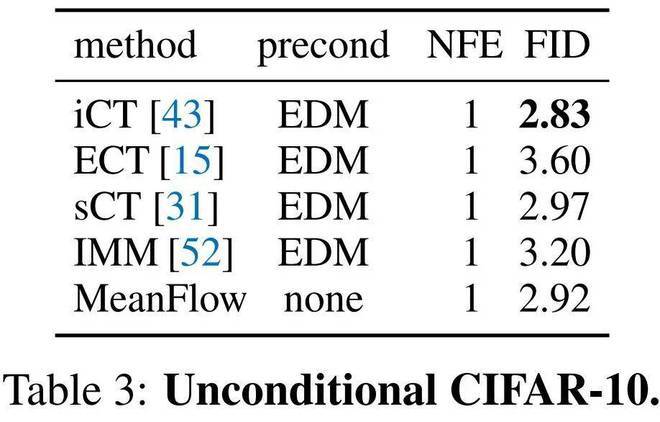
表1为消融实验结果:

最后,展示一些1 - NFE的生成结果。

更多详情请参阅原论文。