

Prompt:这是一个奇幻剧风格的电影场景,描绘了一个人走过一片宁静的田野,到处都是漂浮的灯笼。每走一步,灯笼就会亮起来,散发出温暖、飘渺的光芒。这个人穿着飘逸的东方传统服装,动作优雅,表情安详而又略带沉思。背景是宁静的夜空,点缀着几颗星星和一轮新月,营造出梦幻般的氛围。相机的角度从背后,从中镜头的角度捕捉人物,突出他们的自然动作和发光的灯。

Prompt:一个老人穿着飘逸的绿色连衣裙,戴着一顶宽边太阳帽,在令人惊叹的日落中悠闲地漫步在南极洲冰冷的地形上。他饱经风霜的脸和慈祥的眼睛映照出夕阳的暖色调,夕阳投下长长的影子,使大地沐浴在金色的光芒中。这个男人的姿势直立,自信,双手放在背后。背景是崎岖的冰层和遥远的山脉,天空被涂成橙色、粉红色和紫色。这张照片有一种怀旧和梦幻的感觉,捕捉到了极地的宁静之美。

Prompt:灾难电影风格的戏剧性和动态场景,描绘了一场强大的海啸席卷保加利亚的一条狭窄小巷。河水汹涌而混乱,海浪猛烈地撞击着两岸的墙壁和建筑物。这条小巷两旁是饱经风吹雨打的老房子,它们的外墙部分被淹没和破碎。镜头角度较低,捕捉到海啸向前涌动的全部力量,营造出一种紧迫感和危机感。可以看到人们疯狂地奔跑,加剧了混乱。背景以遥远的地平线为特征,暗示着广阔的世界。
Self Forcing
利用整体后训练弥合训练 - 测试差距
Self Forcing 的核心思想是:在训练阶段就采用与推理时相同的自回归展开方式生成视频。具体实现包含两个关键技术突破:一是,动态条件生成机制。

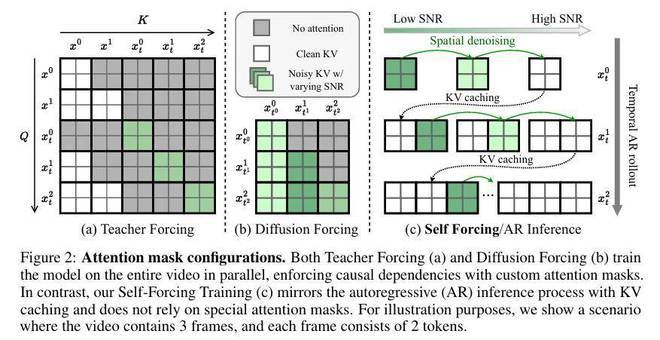
然而,即便采用少步扩散模型,若直接对整个自回归扩散过程执行反向传播,仍会导致内存消耗过大。为解决这一难题,研究者提出以下创新策略:首先进行梯度截断。仅对每帧的最终去噪步骤进行反向传播,将梯度计算范围限制在关键环节。这就像在茫茫大海中抓住了一根救命稻草,虽然艰难,但还有一丝希望。然后是动态步数采样。突破推理阶段固定使用 T 步去噪的约束,在训练时对每个样本序列随机采样 1 至 T 步去噪步骤,并以第 s 步的去噪结果作为最终输出。这种随机采样机制确保所有中间去噪步骤都能获得监督信号。最后是梯度流隔离。通过限制梯度向 KV 缓存嵌入的传播,在训练过程中切断当前帧与先前帧的梯度关联。完整训练流程详见算法 1。

利用滚动 KV 缓存的长视频生成
受大语言模型研究的启发,研究者为自回归扩散模型提出了一种滚动 KV 缓存机制,可以实现无限长视频生成且无需重新计算 KV 缓存。如图 3 (c) 所示,研究者维护固定大小的 KV 缓存区,仅保留最近 L 帧的 token 嵌入。当生成新帧时,首先检测缓存是否已满,若达到容量上限则移除最旧的缓存条目后再存入新数据。在保持 O (TL) 时间复杂度的同时,确保生成每一新帧时都能获得足够的上下文信息。这种设计既实现了无限帧生成能力,又维持了稳定的计算效率。
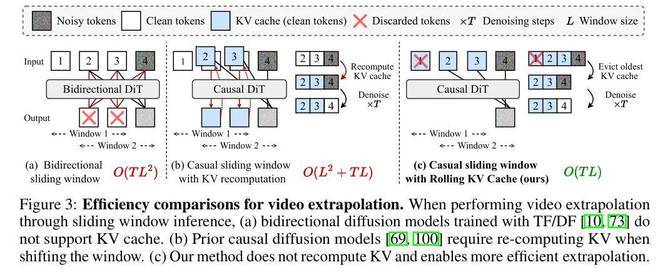
算法 2 详细描述了基于滚动 KV 缓存的自回归长视频生成算法。

实验及结果
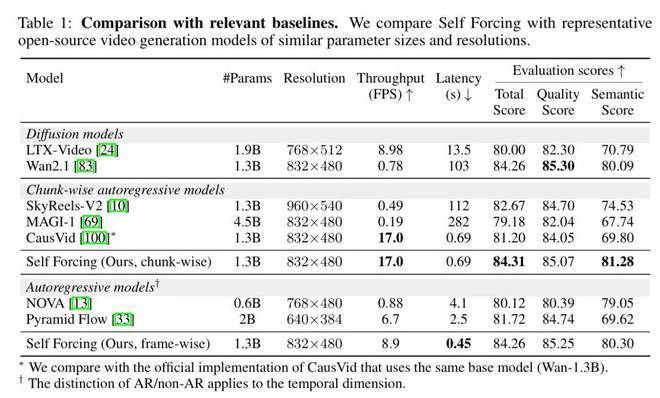
研究者采用 Wan2.1 - T2V - 1.3B 模型实现 Self Forcing,这是一个基于流匹配的模型,可以生成时长 5 秒、16 帧、分辨率为 832×480 的视频。配合 VBench 和用户偏好研究,研究者同步评估了生成视频的视觉质量与语义对齐度。同时,严格测试了 Self Forcing 在实时应用中的效率表现。在单个 NVIDIA H100 GPU 上,研究者综合评估了吞吐量和首帧延迟两项指标,全面衡量实时生成能力。研究者将采用 Self Forcing 算法的模型与规模相近的开源视频生成模型进行比较,包括两个扩散模型(作为初始化权重的 Wan2.1 - 1.3B 和以高效著称的 LTXVideo)以及多个自回归模型(Pyramid Flow、NOVA、SkyReels - V2、MAGI - 1 和同样基于 Wan - 1.3B 初始化的 CausVid)。如下表 1 所示,研究者提出的分块自回归方案在 VBench 评估中全面超越所有基线模型,同时在人类偏好度测试中取得最优成绩。该方案还能实现 17 帧 / 秒的实时吞吐量,配合亚秒级首帧延迟,足以支持直播等实时视频流应用场景。
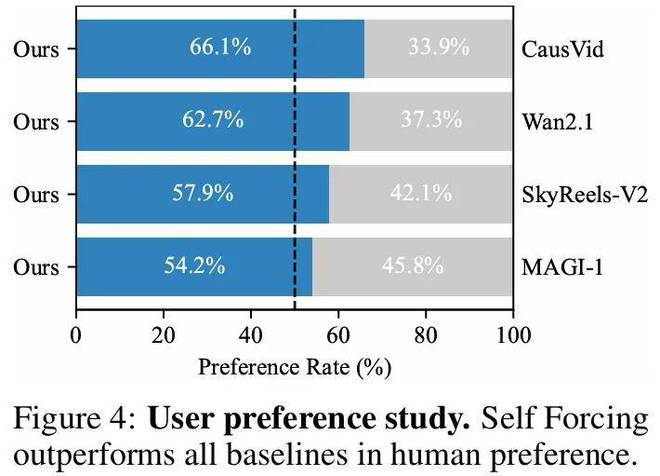
下图 4 展示了用户调研结果,将分块 Self Forcing 模型与多个重要基线模型进行了比较。结果显示,本文方法在所有对比中持续获得最高偏好度,包括作为模型初始化基础的 Wan2.1 多步扩散模型。其中,帧级变体版本在保持强劲生成质量的同时,实现了最低延迟(0.45 秒),特别适合对延迟敏感的实时应用场景。这些实验结果均采用 DMD 损失函数作为优化目标。
采用 SiD 和 GAN 目标函数训练的模型在消融实验中表现出了类似的性能。如下图 5 所示,CausVid 存在误差累积问题,导致饱和度随时间推移不断增加。本文方法在画质上略优于 Wan2.1 或 SkyReels - V2,同时延迟时间缩短约 150 倍。

更多实验细节请参阅原论文。