

5月16日,腾讯发布了最新的混元图像2.0模型,本以为能为这枯燥的生图世界带来一场甘霖,可没想到它虽有革新之意,却也带着让人无奈的“枷锁”。
目前市面上的各类大模型,除了非推理语言大模型的生成外,其他模态大模型的生成过程大多都需要等待。尤其是文生图领域,那“抽卡—等待—抽卡”的方式,就像蜗牛爬行一样,严重影响效率。而腾讯混元图像2.0号称要改变这一现状,主打一个“快”字,支持文生图和绘画生图。无论是输入文字指令、语音指令,还是上传本地图、在线绘制图,都宣称能毫秒级获得高质感图像。可这真的能如我们所愿吗?

从演示案例来看,用户输入“一位女士”,模型生成了一张证件照。接着继续输入“…风景照、沙漠中”,画面背景瞬间变换。再输入“扎着头发、回眸一笑”,画面也飞速切换,最后随着输入结束,画面生成完毕。还有生成“爱因斯坦在东方明珠前自拍”的案例,模型也迅速展现出整个生成过程。这看似很美好,可我们心里清楚,实际使用中会不会出现各种问题呢?
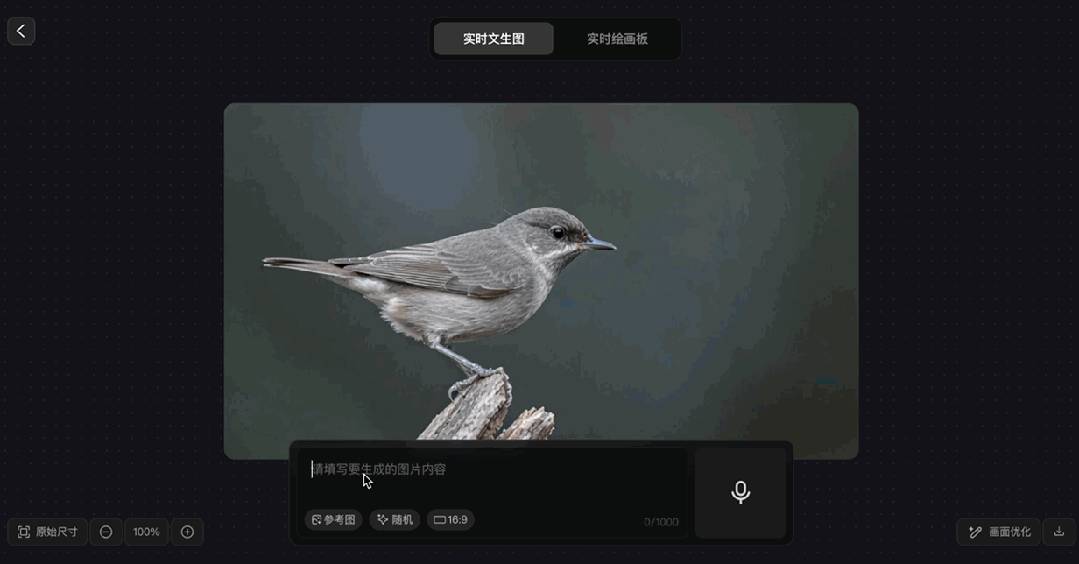
除了文生图,该模型还支持在图片上使用画笔修改的“实时绘画板”,能迅速生成结果。通常绘画过程中的即时反馈能让用户对作品迅速做出调整,可AI图像生成的修改往往是反复投喂产出。如果能在生成过程中实时修改,效率确实会极大提高。可这对于我们普通用户来说,真的能轻松实现吗?
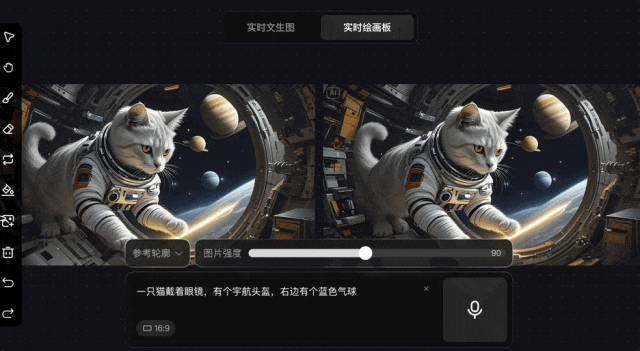
腾讯表示,相比前代模型,该模型参数量提升了一个数量级,得益于超高压缩倍率的图像编解码器以及全新扩散架构,生图速度显著快于行业领先模型。在同类商业产品每张图推理速度需要5到10秒的情况下,混元可实现毫秒级响应,支持用户一边打字或者一边说话一边出图。可即便如此,我们还是满心委屈,因为目前该模型的使用还需注册预约。我们满心期待地想要体验这革新的生图方式,却被这注册预约挡在了门外,就像看到了美味的蛋糕,却被告知要先排队,而且还不知道要排多久。
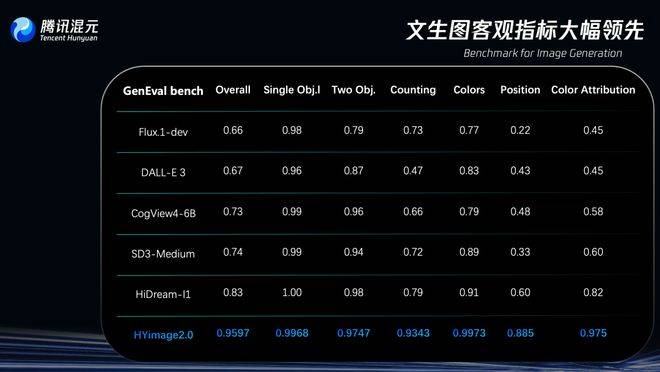
在评分方面,腾讯称混元图像2.0模型在图像生成领域专门测试模型复杂文本指令理解与生成能力的评估基准GenEval(Geneval Bench)上,准确率超过95%,远超其他同类模型。可这又如何呢?我们连使用的机会都还没有,这些数据再好看,对我们来说也只是可望而不可即。
满心期待着混元图像2.0能给我们带来全新的生图体验,可这注册预约却像一道冰冷的墙,让我们的期待只能化作无奈的委屈。真希望腾讯能早日让更多用户顺利体验到这革新的模型啊。