

本文第一作者顾泽琪是康奈尔大学计算机科学四年级博士生,导师为 Abe Davis 教授和 Noah Snavely 教授,研究方向专注于生成式 AI 与多模态大模型。本项目为作者在英伟达实习期间完成的工作。
唉,想象一下,身为一名游戏设计师,要为奇幻 RPG 游戏搭建一个“精灵族树屋村落”场景。那参天古木、树屋、发光的蘑菇路灯、半透明的纱幔帐篷……在传统工作流程里,这简直就是一场噩梦。先得手工建模每个 3D 资产,再逐个调整位置和材质,最后反复测试光照效果,数周的时间就这么没了,真让人无奈啊。
这种困境就像是当前 3D 内容创作领域的一个沉重枷锁。传统 3D 设计软件如 Blender、Maya 功能虽强大,可那陡峭的学习曲线,就像一座难以攀登的山峰。近年来兴起的文本生成 3D 技术,本以为能带来曙光,可要么依赖有限的 3D 训练数据,遇到新场景类型或风格就像无头苍蝇一样容易出错;要么在预测完场景中的物体信息后,要从特定的 3D 模型池中寻找匹配的,最后的场景质量完全取决于模型池里有什么,风格不统一的问题就像一块挥之不去的乌云。
与之形成鲜明对比的是,文本生成 2D 图像技术却一路高歌猛进,像 GPT - 4o、Flux 这些模型,通过海量互联网图像训练,已经能生成布局合理、风格统一的复杂场景图。这不禁让人无奈地思考:能不能让 2D 图像充当“中间商”,先把用户输入文字转化为高质量场景图,再从中提取 3D 信息呢?NVIDIA 与康奈尔大学联合团队的最新研究 ArtiScene,就是在这种无奈下诞生的全新解决方案。

- 文章链接:https://arxiv.org/abs/2506.00742
- 文章网站:https://artiscene - cvpr.github.io/(代码即将开源)
- 英伟达网站:https://research.nvidia.com/labs/dir/artiscene/

图一:ArtiScene 生成的 3D 结果。从左到右的文字输入分别是,第一行:(1) a Barbie - styled clinic room, (2) a space - styled bedroom, (3) a teenager - styled bathroom。第二行:(1) a cute living room, (2) a garage, (3) a operating room.
核心贡献:无需训练的智能 3D 场景工厂
ArtiScene 的核心创新在于构建了一个完全无需额外训练的自动化流水线,这在当前 3D 创作的无奈困境中,就像一道坚韧的光。它将文本生成图像的前沿能力与 3D 重建技术巧妙结合,一共包含五步:
1. 2D 图像作为 "设计蓝图"
系统首先用扩散模型生成等轴测视角的场景图。这种视角常用于建筑设计示意图,能同时呈现物体的长、宽、高信息,且不受场景位置影响。在直接生成 3D 困难重重的无奈下,这种方法利用更成熟的 2D 生成技术确保布局合理性和视觉美感,就像是在黑暗中找到了一条相对平坦的路。

图二:和其他任意的相机视角(左二、三)比,让文生图模型输出等轴测图(左一)更可靠,因为等轴测图默认相机参数是固定的,且没有透视形变。
2. 物体检测与修复
采用两阶段检测策略:先用 GroundedDINO 识别场景中的家具和装饰品,对遮挡部分用补全修复(Remove Anything 模型),再次检测确保完整性,最后得到每个物品的分割掩码。在复杂场景的无奈面前,这种严谨的策略就像是在混乱中努力整理秩序。
3. 3D 空间定位
通过 Depth - Anything - 2 模型估计深度信息,配合自定义投影公式将 2D 坐标转换为 3D 位置。团队发现传统相机投影公式需要调整,于是采用去除深度缩放影响后的公式。这是在面对传统方法局限性的无奈下,坚韧地探索出的新路径。
4. 模块化 3D 资产生成
传统方法通常从现有数据库检索 3D 模型,导致美观度受限,这让人很无奈。ArtiScene 则对场景图中的每个物体分别生成定制化 3D 模型:在得到分割物体图像后,让 ChatGPT 描述其几何特征,再输入单视图 3D 生成模型,为每件家具、装饰品单独建模。这就像是挣脱了预制模型库的枷锁,展现出了坚韧的创新精神。
5. 场景组装
通过单目深度估计,系统将 2D 边界框转换为 3D 空间坐标。并使用 "渲染 - 比对" 的姿势估测机制,生成 8 个旋转角度的物体渲染图,用 Stable Diffusion + DINO - v2 融合模型提取特征,选择与原始场景图最匹配的姿势。后处理阶段还会自动修正物体重叠,确保物理上足够合理,比如椅子不会嵌进餐桌里,花瓶能稳稳立在柜子上。在解决场景合理性的无奈问题上,这种细致的处理就像是在精心雕琢一件艺术品。
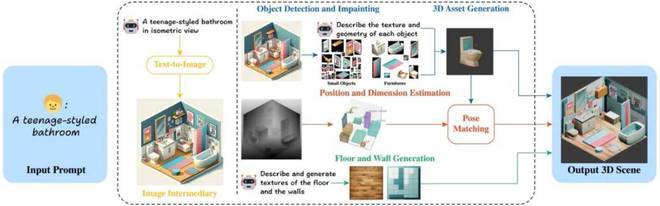
图三:系统流程图
这种设计带来三个显著优势:
零训练成本:完全利用现成模型,无需针对新场景类型微调,在训练成本高昂的无奈下,这无疑是一种解脱。
风格无限:每个物体都按需生成,不受预制模型库限制,打破了风格单一的无奈局面。
可编辑性强:单独修改某个物体不会影响整体场景,解决了修改场景时牵一发而动全身的无奈问题。
实验结果:全面超越现有方案
团队在三个维度进行了系统评估:
1. 布局合理性测试
对比当时最强的 LayoutGPT,在卧室和客厅场景中:
- 物体重叠率降低 6 - 10 倍(卧室 6.48% vs 37.26%)
- 用户调研显示,72.58% 的参与者更青睐 ArtiScene 的布局
- 生成家具数量更多(卧室平均 6.97 件 vs 4.30 件),且分布更自然
2. 风格一致性测试
相比当时效果最好的文生 3D 场景方法 Holodeck,在包含 29 种场景种类和风格的测试集中:
- CLIP 分数提高 10%(29.45 vs 26.73)
- GPT - 4 评估中,95.46% 案例认为 ArtiScene 更符合描述
- 用户调研显示,82.96% 认为风格还原更准确

图四:和之前的 SOTA Holodeck 的比较。
3. 应用灵活性展示
系统支持多种实用功能:
- 物体编辑:单独修改某个模型(如把普通汽车变成黄色保时捷)
- 多场景适配:通过调整参数支持户外场景生成
- 人工引导:允许直接输入手绘设计图替代 AI 生成场景图
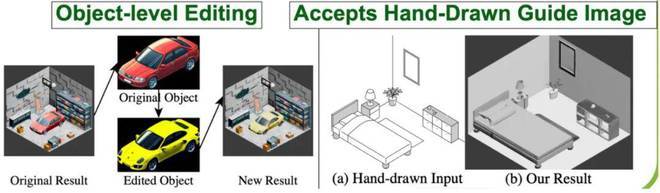
图五:左:物体编辑;右:跳过最开始的文生图环节,直接用人工画的图生成场景。
展望
对于更复杂的多房间场景(如整个博物馆、医院),或者要求特定家具间的位置关系和个数等用户输入,由于文生图模型在训练时就缺乏相关数据,ArtiScene 在最开始就会受限于不够优质的二维图像,这让人感到很无奈。然而,这一模块是可更换的,ArtiScene 不依赖于某一特定模型,未来如果有性能更好的同功能模型,我们也可以很容易把它们替换进来。这种可扩展性就像是在无奈的现状中怀揣着坚韧的希望。
本项目创新地采用二维图像来引导三维场景生成,并用 LLM、VLM 等大模型构成了一个鲁棒的系统,在生成结果的美观度、多样性和物理合理性上都远超之前的同类型方法。作者希望他们的工作可以启发未来更多关于具身智能、AR/VR、室内 / 室外设计的思考,在无奈中展现出了坚韧的探索精神。